
本篇介紹Mplus的「結構方程模型(Structural Equation Modelling, SEM)」之語法內容,並透過例題向大家示範如何分析撰寫SEM的語法。
雖然Mplus的語言以英文為主,但為了快速讓大家瞭解Mplus的語法基礎概念,所以我們在介紹Mplus每個語法細節後面加註「!」之符號,並在此符號後面說明該語法的用途,但是請大家實際在分析時,建議在「!」的文字仍以英文為主,請勿在Mplus中撰寫中文,以避免Mplus執行失敗。
【例題】結構方程模型分析
A、B、C為自變數
D為中介變數
E為依變數
【例題Mplus語法】
TITLE: SEM analysis
!這邊可以填寫這個分析方法的名稱,或你想要的檔名名稱均可。
DATA: FILE = SEM.dat;
!請將數據檔案與Mplus檔案放在同一個資料夾,並直接將數據檔案放在「=」的右邊,每次結束一個語法設定請記得加上「;」
VARIABLE: NAMES = A1-A8 B1-B8 C1-C8 D1-D8 E1-E8;
!請依據數據檔案由左至右的順序,將變數命名,這個範例有五個構念,所以將他們用不同代碼區分,之後會比較好辨認,其中A、B、C均為自變數,D為中介變數,E為依變數。
USEVARIABLE= A1-A8 B1-B8 C1-C8 D1-D8 E1-E8;
!請將這次分析有用到的變數羅列在「=」的右邊。
MODEL:
A by A1-A8;
B by B1-B8;
C by C1-C8;
D by D1-D8;
E by E1-E8;
D E on A B C;
E on D;
! by的設定做為潛在變項與觀察變項之連結,此部份A、B、C、D、E分別代表五個潛在構念,而A1-A8、B1-B8、C1-C8、D1-D8、E1-E8則均為觀察變項。
!by 後面第一個觀察變項的路徑係數為1。
! on的設定為探討潛在構念之預測關係。
OUTPUT: Sampstat STDYX;
!若要產出一般為標準化的結果請輸入「Sampstat」,若想要知道標準化結果則請輸入「STDYX」,在說明因素負荷量時,多以標準化解為說明。
【例題Mplus結果】
成功跑出Mplus結果時會出現一個新的output檔案,請將這個檔案開啟,首先會先看到Mplus當初撰寫的語法。

接著,結果會告訴你在這筆資料中有幾筆樣本,幾個變數,建議可從此部分檢查是否符合原始資料。
此範例原始資料包含328個樣本,40個觀察變項,5個潛在構念。

Mplus也會提供基本的統計分析,例如平均數與相關分析。
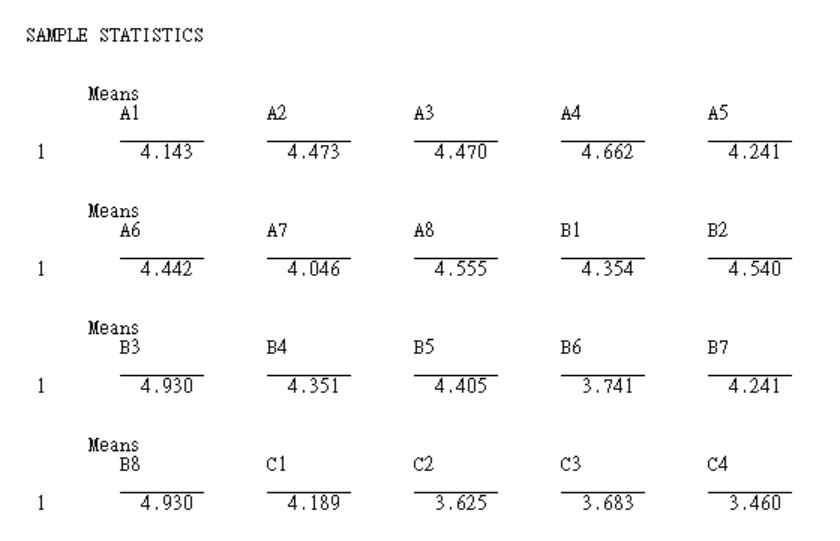
在「correlation」之處,可查看每個觀察變數之相關係數。

Mplus會提供模型適配度,如χ2、CFA、TLI、RMSEA、SRMR等適配度指標。

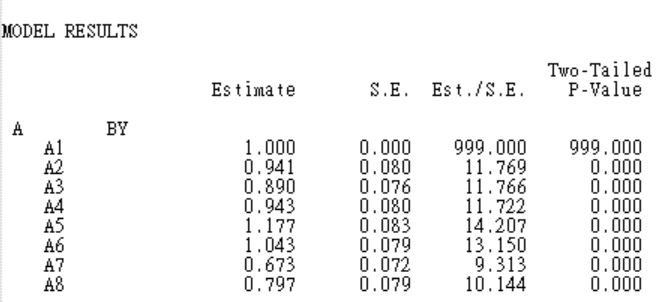
在「Model Result」的部分,可以看到未標準化的因素負荷量,如A1的因素負荷量設先被設定為1,A2的未標準化因素負荷量為0.941,以此類推。
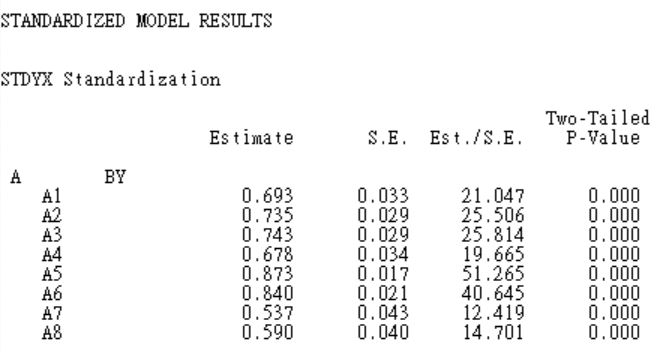
在「standardized model results」的部分,則是提供因素負荷量的標準化解,如A1的標準化因素負荷量為0.693,A2的標準化因素負荷量為0.735。
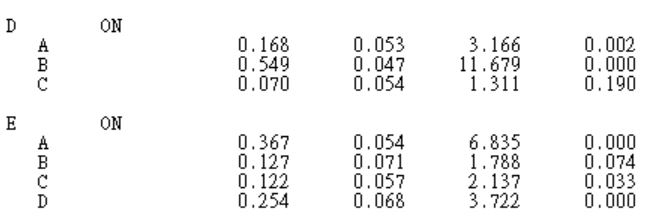
最後,五個潛在構念之預測關係如下,根據分析結果顯示:A和B正向顯著預測D(中介變數);且A、B和D亦均正向顯著預測E(依變數),支持D在「A與E」以及「B與E」關係中具有部分中介效果。
Mplus的SEM你學會了嗎?



